はじめに
はじめまして。サイカでソフトウェアエンジニアをやっているshohhei1126です。
こちらの記事でも触れている通り、サイカでは1年以上の期間をかけて、モノリスで動いていた自社サービスをマイクロサービス(Microservices Architecture)に作り替えました。
マイクロサービス化を進めるということは、マイクロサービスたちが相互作用しながらユーザに価値を届ける一方で、複雑化したシステムの状態を把握することが難しくなる課題を新たに抱えることを指します。
この課題にはオブザーバビリティを高めることで解決を図るのが主流となっています。オブザーバビリティはある意味バズワードとなっており明確な定義がまだまだ定まっていないところもありますが CNCF Observability Technical Advisory Group を見てみると「目的設定が大事」と主張されています。
では、サイカにとっての重要なオブザーバビリティとは何か、というところから始めてその後具体的な方法へと話を進めてみたいと思います。
サイカプロダクトの特徴と問題
サイカのメインサービスに Magellan があります。Magellanは、広告も広告以外もあらゆるマーケティング要因の売上影響を可視化する toB 向けサービスです。
基本的には担当のコンサルタントが営業時間中に広告の売上影響に関して分析する際にプロダクトを使用します。特徴的な点は、データや設定によって分析の処理時間が大きく異なることです。数百ミリ秒で完了するものもあれば数十秒かかるものまであります(主に社内向けの分析ツールであるためこの程度のレイテンシーは許容しています)。
メトリクスとしてレイテンシーなどを監視することが多いと思いますが、Magellan では一律にパフォーマンスを計測してしまうと値の振れ幅が大きくなる傾向があります。これでは問題があるのかないのか判断がつきにくくなります。
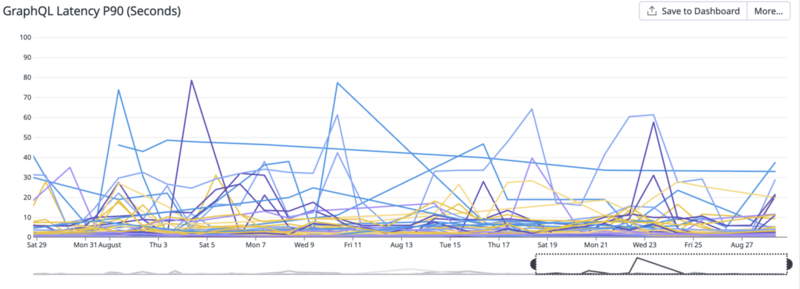
以下のグラフは各APIのレイテンシーを90パーセンタイルでとったものですが、このグラフから何かを読み取るのはなかなか難しいものがあります。ということでこのレイテンシーを正しく評価できる状態にすることを目的に改善を進めます。
特定のデータセットと定点観測
前述のような状況を解決するために、とてもシンプルな方法ですがデータセットごとに確認できるメトリクスの作成を考えます。
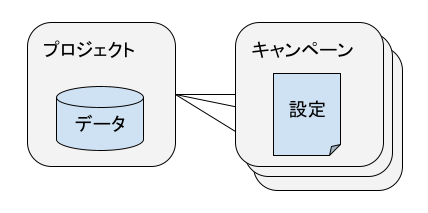
Magellanではプロジェクトとキャンペーンという概念があります。一対多の関係にありプロジェクトには基本となるデータがあり、キャンペーンは分析に関する設定を持ちます。ということでこのプロジェクトとキャンペーンごとに各APIのレイテンシーを確認することができればよさそうです。
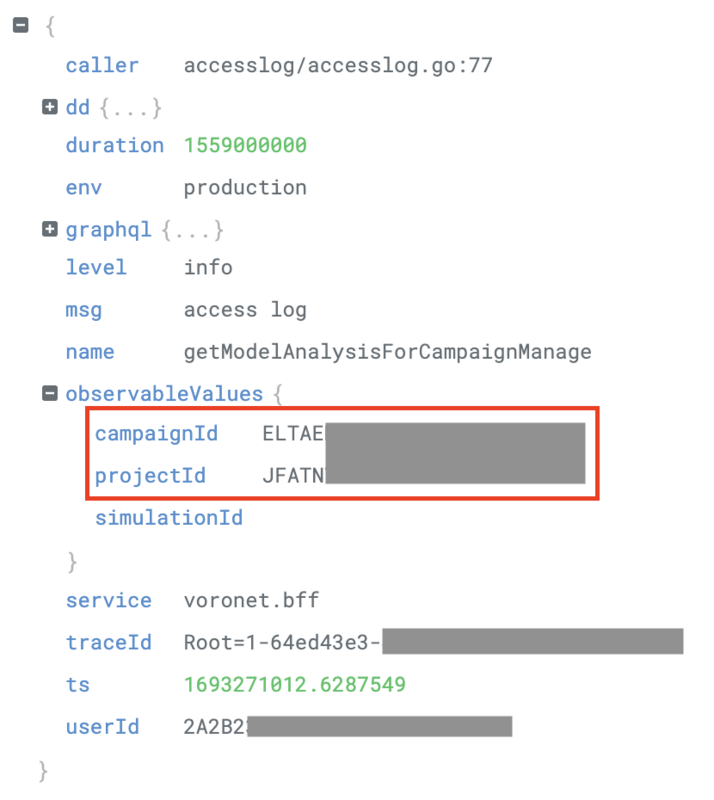
サイカではDataDogを使用しているので実装方法は以下のようにアクセスログにこれらのIDを追加し、ログからメトリクスを生成する際に追加したIDたちをgroup byに設定することで実現できます。
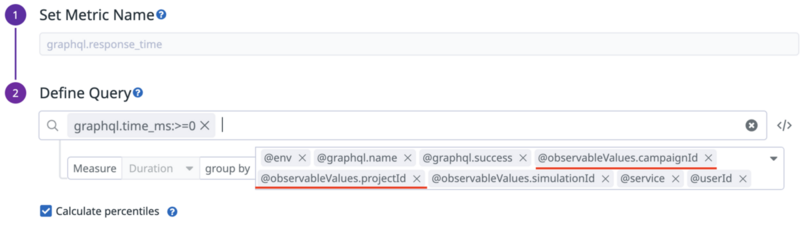
これでAPIのレイテンシーをIDで絞ることができるようになります。
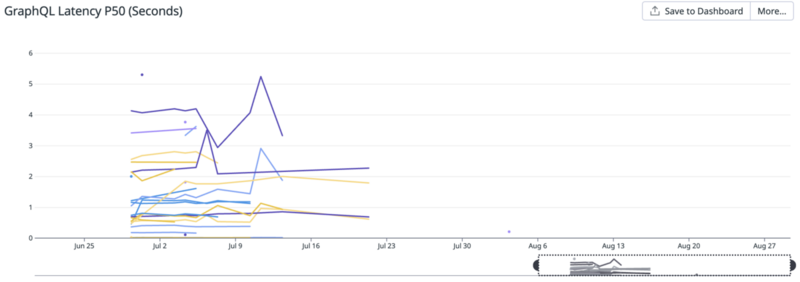
しかしこれにはまだ問題があります。特定のプロジェクトやキャンペーンは当然分析が終われば使われなくなるため、レイテンシーの推移を長期的に観察することができません。以下のグラフはAPIレイテンシーを特定キャンペーンで絞ったものですが、使われた数週間だけしか可視化されません。
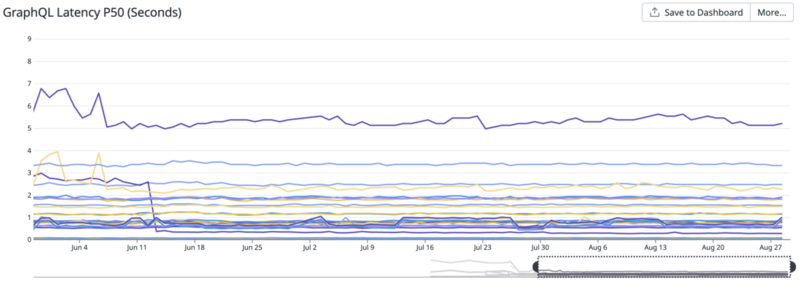
そこで定点観測用のプロジェクト、キャンペーンを用意し負荷の少ない深夜帯に機械的にリクエストを送ることにしました。これでようやく指標として使えるレベルになります。
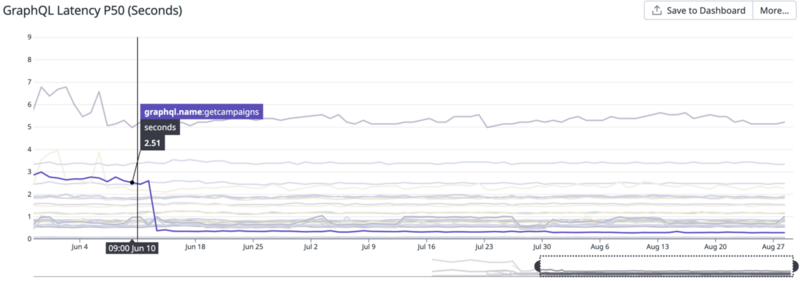
以下はとあるAPIのレイテンシーですがこの指標によって改善が必要なことに気づくことができ、さらに改善後の効果検証にも使うことができました。
残された問題とさらなる進化
これまで触れてきた指標をもとに日々運用することが可能になってはいますが、もちろん問題もまだまだ残っています。定点観測という制約上更新系のAPIが網羅できない点、その他のデータや設定のバリエーションに対するレイテンシーの評価ができない点などです。
前者は基本的にデータの更新だけで数理処理が行われないため一律にレイテンシーを見ても比較的問題を発見しやすいです。
しかし後者が厄介者で数理処理の特性上、解決がなかなか難しいのが現状です。分析の処理時間はデータとその設定に依存するため、それらをもとにS, M, Lといったクラス分けができると良さそうに思えます。ただどの設定がどの程度影響するのかを判断できず今のところ実現に至ってはいません。
この数理処理のレイテンシーを正しく評価する、というのが残された問題 = オブザーバビリティを高める目的、ということで今後も取り組んでいきたいと思います。
おわりに
今回は抽象的な概念であるオブザーバビリティを目的ドリブンな考え方でここまで話してきました。
APIのレイテンシーやエラー率、CPUやメモリの使用率、各種ログ、トレーシングなど誰の目にも明らかに必要なものは当然あります。
そこから更に各プロダクトの特徴に合わせてよりシステムの状態を正確に把握できるように思考を深めていくことで、オブザーバビリティというものが単にバズワードにならずに有効活用できるのではないでしょうか。
少しでもお役に立てれば幸いです。最後まで読んでいただきありがとうございました。