はじめに
今回は自社サービスをマイクロサービス(Microservices Architecture)に作り替えるリアーキテクチャプロジェクトにおいて、どのようにコア・バリューである数理統計処理を移行させたのかについてお話していきます。
私は、サイカでソフトウェアエンジニアとして、主にWebアプリケーション部分を開発している森永と申します。
数理統計処理の移行というと、何か特別な技術を使っているかのように見えますが、実際には通常のアプリケーションと同じ仕組みで動いているため、通常のアプリケーションにおけるリアーキテクチャと同じように要件から戦略を立て、実行と移行後の確認を行っていきます。
システム構成
先に前提知識として、今回のリアーキテクチャにより、どのようなシステム構成の変化があるのかを軽く説明します。
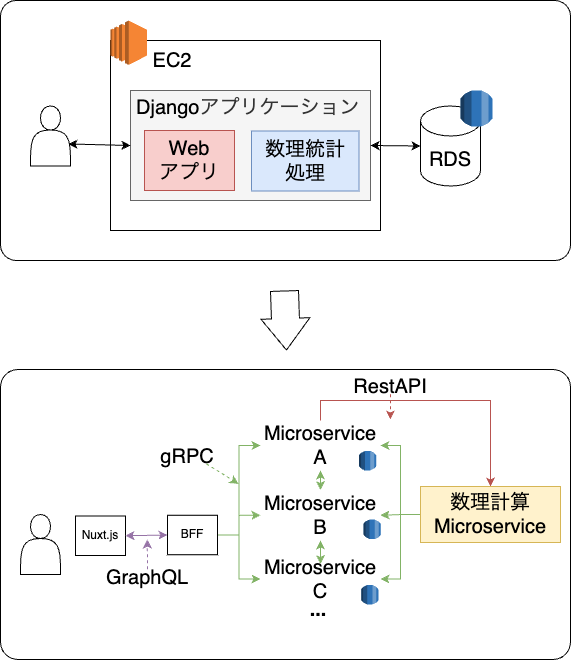
旧システムは、Djangoを使ってモノリスに構築されており、Webアプリケーションと数理統計処理が同じコードベース上で密結合をしていました。
新システムでは、複数のマイクロサービスを組み合わせて一つのアプリケーションを提供する形となります。マイクロサービス間のやり取りはgRPCを使うことになっていました。
このような前提の中で、数理統計処理をどのように新システムに組み込むかは、いくつかの戦略が考えられますが、もちろん求められている要件もあります。 まずは、どのように移行戦略を立てていったのか説明します。
数理統計処理を移行する要件
数理統計処理を移行させる上で、大きく4つの要件がありました。
- 全体のリアーキテクチャと完了時期を揃える。
- 新システムにおいて、パフォーマンスを低下させない。
- 後に数理統計処理を作り直す計画がある。
- 入力値に対する出力値を一致させる必要がある。
全体のリアーキテクチャと完了時期を揃える。
数理統計処理のリアーキテクチャと平行して、全体のアプリケーションのリアーキテクチャが実行されていたのですが、両方が揃わない事には環境を動かすことができません。
なので、当たり前といえばそれまでなのですが、全体のリアーキテクチャからあまり遅れることなく、作業を完了させる必要がありました。
ただ、リアーキテクチャ後の数理統計処理もマイクロサービス化された他のアプリケーションと協調して動くため、他のマイクロサービスの実装が進んでいないと、結合確認が行えません。むしろ他のマイクロサービスが全て完了した後にしか結合確認に進めないのです。。。
方針:gRPCを活かして先にモックを作成し、他のマイクロサービスの進捗から自由になる
新システムにおいて、パフォーマンスを低下させない。
今回のリアーキテクチャの目的としては、新規開発や運用負荷の軽減という目的がありますが、元のシステムより遅いシステムとなってしまっては、機能不全に陥ってしまいます。
もともと数理統計処理自体は、数理計算の負荷が高いため数ミリsecのような高パフォーマンスが求められるわけではありませんが、日常的に分析を行う業務フローを考えると、遅くなることは避ける必要がありました。
その上で一番問題となるのは、マイクロサービスという構成です。
分析においては、分析の元となるデータや、各種設定情報をまず集める必要があるため、複数のマイクロサービスに対して、ほぼすべてのデータを要求する必要があり、どうしてもオーバーヘッドが生じてしまいます。
特に、分析の元となるデータは、構造は簡単ですが、量があるため変換や転送の時間がかかります。
方針:キャッシュの仕組みを作成し、オーバーヘッドを小さくする
後に数理統計処理を作り直す計画がある。
最後に、今回移行を行う数理統計処理は実は半年〜一年ほど運用した後にゼロから作り直したより効率的で拡張性のある数理統計処理に置き換えされることが決まっていました。
つまり、なるべく疎になるように設計しておくことで、後の置き換え時にスムーズに対応ができることになります。
今回は移行元の数理統計処理がDjangoで動いていたため、移行のコード変更を容易にするためRestAPIをI/Fとしつつ、他のサービスを呼び出す部分はgRPCを採用することとしました。
方針:数理統計処理のI/FをRestAPIとし、必要なデータや設定はgRPCを通じて取得する。
入力値に対する出力値を一致させる必要がある。
今回最も重要なポイントとして、分析結果が変わってはならないという要件がありました。
もちろん一般的なWebアプリケーションにおいても、リアーキテクチャでは前後で動作は変わってはならないのですが、同様に数理統計処理であっても振る舞いを変えてはいけません。
もし振る舞いが変わってしまうと、分析結果が変わってしまい、お客様に対して一貫したレポーティングができなくなることを意味します。
Webアプリケーションでは、機能の動作が前後で同じことを自動テストや人の目を使って主に確認していくかと思うのですが、今回比較するのは、数理統計処理が出力する1.3453249053というような数字です。
数理統計処理が出力する結果を利用する際に、別の数字を四則演算することにより、どんどん誤差が大きくなってしまうため、これを1e-7の精度(0.0000001)で一致させる必要がありました。
これでも精度としては不十分なため、現在サイカでは完全一致させるための取り組みを行っております。
方針:新旧の分析結果を比較する仕組みを構築する。
上記4つの中で最も重要かつハードルが高いのが最後に紹介した数値の一致です。
そこで大きく3つの戦略を立てました。
- ローカルにモック環境を作成し、新旧の出力を開発中に確認できるようにする。
- 既存コードの変更を最小限とするため、DB層のみを入れ替えることで動作するようにする。
- 新旧のシステムを実際に稼働させ比較するためのアプリケーションを作成する。
この3つの戦術をどのように実行していったのかを詳細にご説明します。
具体的にどうやったか
ローカルにモック環境を作成し、新旧の出力を開発中に確認できるようにする
精度高く移行作業を進めるにあたって、最も怖いことは「完成しないとわからない」です。
なので、事前に各マイクロサービスのgRPCをモックとして利用できるアプリケーションを準備しました。
このアプリケーションは、旧環境のDBデータを入力するだけで、新環境でのgRPCレスポンスをモックしてくれる便利なものです。
このモックアプリケーションを先に作っておいたことで、コードを少し編集して、APIから得られた新旧のデータの比較をするというサイクルを小さく回せるようになりました。
あれ?単体テストを実行すれば良いんじゃない?と思われたそこのあなた!
実は既存のコードにはほとんど単体テストが無く、また、仕様も失われているため単体テストを書いたとして仕様をカバーできているかわからない。そして一人で単体テストを書いていたらプロジェクトの完了が来てしまう。
という状況であったため、実際のデータを複数使いE2Eテストの状態を実現することが最もコスパが良さそうだという結論になりました。
既存コードの変更を最小限とするため、DB層のみを入れ替えることで動作するようにする。
既存のコードに手を入れれば入れるほど、ロジックを変更してしまうリスクが高まってしまうため、DjangoのORMだけを置き換えることで実現することにしました。
今回移行を行う数理統計処理は、後ほど作り直す予定だったため、全てをリファクタリングする必要がなかったため取れる方法です。
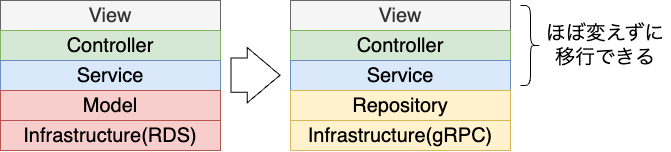
とはいえDjangoのORMはActiveRecordの方式を採用しているため、データオブジェクトとDBアクセスの発生するメソッドが密に紐づいています。
そこで、先にRepository層を導入し、DBアクセスとデータオブジェクトの分離を行いました。
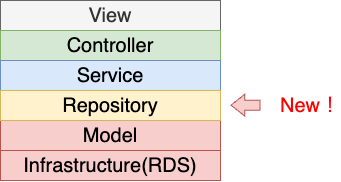
やり方は地道にfindを読んでいる箇所や、リレーションを取得している箇所をgrepして、Repositoryのメソッドに書き換えをしていきます。
Repositoryのメソッド内では、DjangoのORMのメソッドを呼び出しているため、影響は無い状態になるはずです。
一通り書き換えながら新旧のAPIで差分が無いことも確認をしていきます。
ここまで来ると作業としては折返しで、ここからrepository層の内部をgRPC呼び出しに置き換えを行っていくのですが、新旧でデータ構造が異なるため、そのまま対応するgRPCメソッドを呼ぶことができません。
なので、まずはgRPCメソッドを呼び出して旧データに変換を行い、パフォーマンスを考慮しオンメモリキャッシュとして保持する仕組みを作成します。
実は旧データに変換するためには、関連するほぼすべてデータが必要であり、それを必要毎に毎回行うとパフォーマンスが明らかに低下することが推測されたため、API呼び出しを受けた時点で、対象の旧データ変換をすべて行い、その後に高速にアクセスできる状態を作りました。
ただし、Djangoはマルチスレッドでメモリ空間を共有しているため、スレッド数を制限して実行する必要があります。
キャッシュの仕組みについては、Djangoがもっているメソッドキャッシュの仕組みを少しハックする形で実現しています。


いわゆるmissの場合には、メソッドを実行するという仕組みですが、メソッド内部はRuntimeErrorを発生する形になっており、事前にgRPCから変換したキャッシュを該当のキーに詰めておき、正常に新旧のデータ変換ができなかった場合エラーになります。
以上の変更を行うことで、アプリケーション層にはほぼ手を入れずにgRPCへの移行を実現させました。
新旧のシステムを実際に稼働させ比較するためのアプリケーションを作成する。
結合確認の後は、旧環境の移行対象すべてのデータに対して数値の一致を確認する(地獄のような)作業が予定されており、新旧のシステムに対して網羅的に数値検証を行うために、CatDogという仕組みを作成しました。
CatDogは大きく2つに別れており、(マイグレーションにゃんこの)mig-nyanと、(忠犬のように結果比較を行う)veri-dogが組み合わさっています。
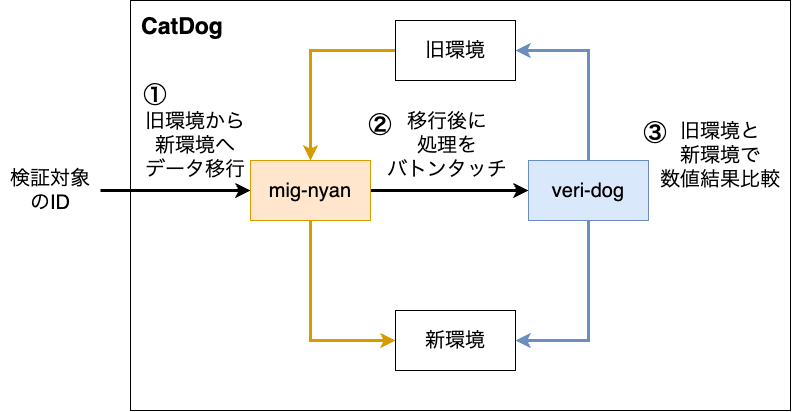
mig-nyanは、名前の通り旧環境のデータを新環境に移行するアプリケーションです。
veri-dogは、APIレベルでのE2Eテストを実行するアプリケーションになっており、テスト対象のAPIを指定すると、リクエストパラメータを変化させたシナリオパターンを生成する仕組みになっています。
これによって、分析実行時に指定する細かいエッジケースのパラメータ指定も再現を容易にできるようになっています。
この2つを大量の移行対象に対して実行していくために、ArgoWorkflowのパラレル実行を利用しました。
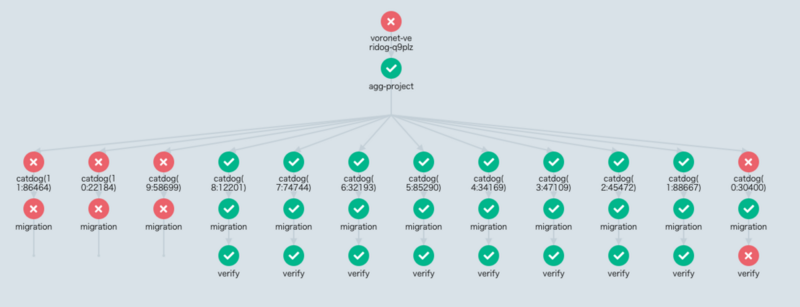
視覚的に実行状態を捉えやすいため気に入っており、またArtifactという形で結果ファイルを出力したりもできます。
そこで、veri-dogの実行結果をxunitの形式で出力させ、それをhtml変換されたリッチな形で見れるようにしました。
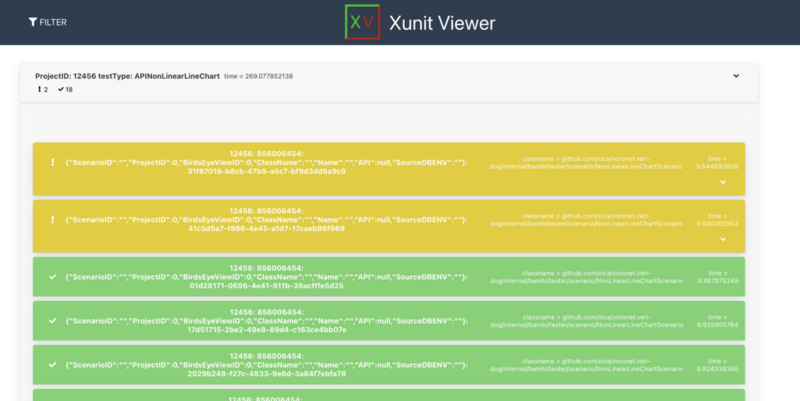
通常のログを確認する形で検証結果を確認する場合、目がショボショボしてきてつらいのですが、これにより少しはテンションを挙げられます(笑)
また、他の方に検証結果の確認を依頼する場合にも、赤か緑か確認してもらえば良いので説明が簡単でした。
より精度高く移行するために
ここまでで、いかに壊さず作業を進めるか、いかに検証を効率的に実行できるかを実現するために色々戦略を取ってきましたが、やはり現実のデータでは上手く数値の一致ができません。
小数点以下3桁までは合っているが、それ以降が異なるや、数値が大きいデータを利用しているとズレてしまうや、一応1e7の精度だが、怪しいといった具合です。
環境差分を限りなく無くす
旧環境はec2上、新環境はeks上で実行されていましたが、ローカルのDocker上で新旧の環境を動作させて検証しているときには発生しない数字差分が出ていることで、どうやら環境差によって差分が発生していることがわかりました。
数値計算で利用している、ライブラリのnumpyやscipyは同じバージョンであっても、CPUの命令セットに合わせて環境毎にバイナリ化されていますが、そのバイナリを比較したりと色々探してみましたが、分からず。
旧環境をeks上に構築しなおすことで解消されることがわかったため、新旧で環境を揃えて検証を行う方針となりました。
同じデータでも同じではない
環境だけでなく、並び順も結果に影響を与えることがわかりました。
分析ロジック的には、ベクトル計算を行うため本来並び順は影響を及ぼさないはずなのですが、全く同じデータを利用していても入力順序が異なることで、結果に大きくズレが発生することがわかりました。
おそらくパラメータを選択するときの選択順序が変わってしまうことにより、しきい値を超えるタイミングが変化してしまうことが原因っぽいのですが、ココ!という箇所は特定できず。
並び順を揃える方針で精度を高めることになりましたが、新環境では旧環境の並び順を完全に再現することができないため、新たにデータの並び順を揃えるロジックを追加して対応しました。
いずれも旧環境の挙動自体が変化してしまう
いずれの対応も数値を一致させるためには必要な変更ではある一方で、旧環境で出力される結果が、多少変化してしまうことにはなってしまいます。
ただ、単体テストが無い以上APIレベルで数値が揃わないと、分析ロジックが変化していないことを保証することもできません。
旧環境と完全に動きを揃えるのか、リアーキテクチャで分析ロジックを破壊していないことを保証するのか。
どちらを優先するかのトレードオフを行う必要がありました。
今回は完全に動きを揃える方針では工数がかかりすぎてしまい、リアーキテクチャプロジェクト全体の完了時期が未定になってしまうため、分析ロジックが変わっていないことを保証することを優先することとし、分析やレポーティングを行う部署にも丁寧にコミュニュケーションしていきました。
最後に
今回はリアーキテクチャプロジェクトにおける数理統計処理の移行についてお届けしました。
基本的には通常のアプリケーションと同じように、計画を立てて一つづつ検証しながら進めていくのが重要だったのですが、すべてを真新しく作るのではなく、旧アプリケーションの分析結果と整合性を取りながら進める必要があった点は難易度が高くなるポイントかと思います。
まだまだリアーキテクチャプロジェクトの本丸であるgolangへの書き換えや、フロントエンドの刷新など面白そうなテーマがありますので、引き続きご期待ください。